
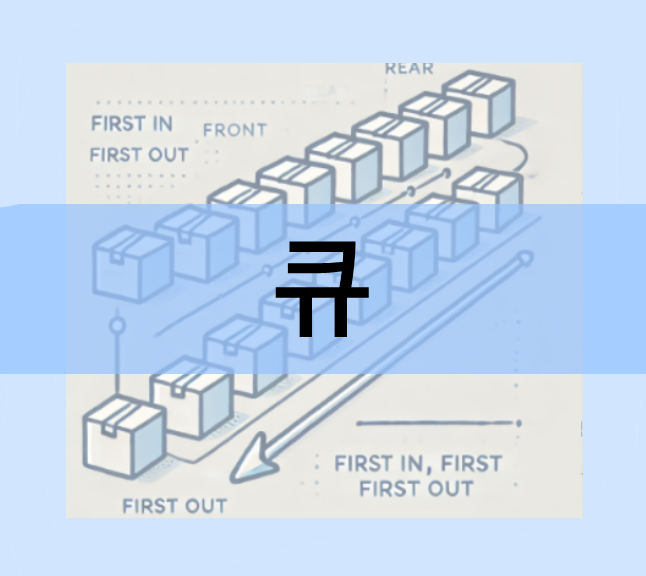
큐(Queue)는 데이터를 순서대로 처리하는 기본적인 자료 구조 중 하나로, 선입선출(FIFO, First In First Out) 원칙을 따릅니다. 큐의 동작 방식은 먼저 들어온 데이터가 먼저 처리되는 구조로, 마치 일상에서 줄을 서는 것과 비슷합니다. 예를 들어, 은행에서 순번대로 고객을 응대하거나, 음식점에서 주문을 처리할 때도 이러한 구조를 사용합니다.
큐의 특징과 동작 원리
큐는 두 가지 주요 연산을 중심으로 동작합니다:
- 삽입(Enqueue): 데이터를 큐의 끝에 추가하는 작업입니다.
- 삭제(Dequeue): 큐의 앞에서 데이터를 제거하는 작업입니다.
또한 큐에는 peek 또는 front라는 연산도 존재하며, 이는 큐의 가장 앞에 있는 데이터를 확인하되 제거하지는 않습니다. 이러한 연산을 통해 큐는 데이터를 순서대로 처리할 수 있게 됩니다.
class Queue:
def __init__(self):
self.items = []
# Enqueue: 큐의 뒤에 요소를 추가
def enqueue(self, item):
self.items.append(item)
# Dequeue: 큐의 앞에서 요소를 제거하고 반환
def dequeue(self):
if not self.is_empty():
return self.items.pop(0)
else:
return "Queue is empty"
# 큐가 비어있는지 확인
def is_empty(self):
return len(self.items) == 0
# 큐의 가장 앞에 있는 요소를 반환
def peek(self):
if not self.is_empty():
return self.items[0]
else:
return "Queue is empty"
# 큐의 크기 반환
def size(self):
return len(self.items)
# 큐 사용 예시
queue = Queue()
queue.enqueue(1)
queue.enqueue(2)
queue.enqueue(3)
print(queue.dequeue()) # 출력: 1
print(queue.peek()) # 출력: 2
print(queue.size()) # 출력: 2큐의 구현 방식
큐는 일반적으로 배열(Array)이나 연결 리스트(Linked List)로 구현될 수 있습니다.
- 배열 기반 큐: 고정된 크기의 배열을 사용하여 큐를 구현할 수 있습니다. 이 방식에서는 배열의 앞과 뒤를 나타내는 두 개의 포인터(Front와 Rear)를 사용하여 큐의 시작과 끝을 관리합니다. 그러나 배열 기반 큐의 경우, 공간이 고정되어 있어 배열이 꽉 차면 더 이상 데이터를 삽입할 수 없다는 단점이 있습니다. 이를 해결하기 위해 원형 큐(Circular Queue)를 사용하기도 하는데, 이는 배열의 끝과 시작을 연결하여 공간을 효율적으로 활용할 수 있도록 합니다.
- 연결 리스트 기반 큐: 동적 메모리를 사용하는 연결 리스트를 통해 큐를 구현할 수도 있습니다. 이 경우에는 크기에 제한이 없으며, 새로운 노드(Node)를 생성하여 큐의 끝에 추가하고, 삭제 시에는 큐의 앞쪽 노드를 제거하는 방식으로 동작합니다.
큐의 활용 사례
큐는 다양한 분야에서 활용되며, 대표적으로 다음과 같은 사례가 있습니다:
- CPU 스케줄링: 운영체제에서 프로세스를 처리할 때, 각 프로세스는 큐에 들어가 순서대로 CPU 자원을 할당받습니다.
- 프린터 작업 처리: 프린터는 인쇄 명령을 큐에 쌓아두고 순서대로 인쇄 작업을 처리합니다.
- 네트워크 패킷 처리: 네트워크에서는 데이터 패킷이 순서대로 전송되고 처리되는데, 이 과정에서 큐가 활용됩니다.
큐의 시간 복잡도
큐의 주요 연산은 일반적으로 O(1)의 시간 복잡도를 갖습니다. 삽입(Enqueue)과 삭제(Dequeue) 연산은 각각 큐의 끝과 앞에서 일어나므로 매우 빠르게 처리됩니다. 다만, 배열 기반 큐에서 비효율적인 메모리 이동이 발생하는 경우(예: 배열이 꽉 찬 경우) 시간 복잡도가 O(n)으로 증가할 수 있으며, 이를 방지하기 위해 원형 큐 또는 연결 리스트 기반 큐를 활용합니다.
큐의 종류
기본적인 선입선출 큐 외에도 다양한 큐의 변형이 존재합니다:
- 원형 큐(Circular Queue): 앞서 언급한 것처럼 배열의 시작과 끝을 연결하여 공간을 효율적으로 활용하는 큐입니다.
- 우선순위 큐(Priority Queue): 각 데이터에 우선순위가 부여되어 있어, 일반적인 큐와 달리 우선순위가 높은 데이터가 먼저 처리되는 구조입니다.
- 덱(Deque, Double-Ended Queue): 큐의 양쪽 끝에서 삽입과 삭제가 모두 가능한 구조입니다. 이를 통해 선입선출과 후입선출(LIFO, Last In First Out) 모두를 구현할 수 있습니다.
큐 사용 시 고려할 점
큐를 사용할 때는 메모리 관리와 연산의 효율성을 고려해야 합니다. 배열 기반 큐의 경우 공간이 고정되어 있어 메모리 사용이 제한적이며, 연결 리스트 기반 큐의 경우 동적으로 메모리를 할당하기 때문에 메모리 사용이 유연하지만 관리가 필요합니다. 또한, 데이터의 삽입과 삭제 연산이 빈번한 경우 큐의 선택과 구현 방식에 따라 성능 차이가 발생할 수 있으므로, 상황에 맞게 적절한 큐의 형태를 선택해야 합니다.
큐는 데이터 처리 순서를 관리하고 싶을 때 유용하게 사용되는 자료 구조입니다. 선입선출 원칙을 따르며, 배열 또는 연결 리스트로 구현이 가능하고, 다양한 변형 형태를 통해 여러 문제에 대응할 수 있습니다. 큐의 효율적인 사용을 위해서는 상황에 따라 적합한 구현 방법과 큐의 종류를 선택하는 것이 중요합니다.
'공부 > 컴퓨터' 카테고리의 다른 글
| 스택의 개념/동작원리/장점/단점/활용 등 (39) | 2024.09.25 |
|---|---|
| 배열의 개념/특징/구조/장점/단점/구조비교 (40) | 2024.09.24 |
| 저급언어 VS 고급언어 (33) | 2024.09.20 |
| 다양한 프로그래밍 언어들(Python/Java/C++/JavaScript/C#/PHP) (47) | 2024.09.11 |
| 가우스 소거법(계수행렬/확대행렬/기본행연산) (15) | 2024.09.10 |



